Deepfake Detector - from crawler to cloud interface
TL;DR
We designed and shipped an end-to-end pipeline: custom short-video crawler → cloud storage → face-aware frame sampling → multi-model voting → auditable API and web UI. It’s pragmatic, scalable, and easy to extend with better models or new sources.
Introduction
This started as a uni project that we treated like a product. Goal: ingest short-form videos, analyze them with multiple ML models, and expose trustworthy results through an API and a small web app. Human reviewers can verify detections to keep the system honest and continuously improve it.
What made it hard
- Short-video platforms are hostile to automation (cookie walls, infinite scroll, dynamic markup). We built a resilient crawler instead of fighting brittle scrapers.
- Models disagree. We needed an ensemble and a clear aggregation strategy that works per frame and per video.
- Inference is spiky. The system had to scale up quickly during crawls and scale down to near-zero cost the rest of the time.
- Auditability. Every detection had to be reproducible with model version, parameters, and timestamps.
Architecture at a glance
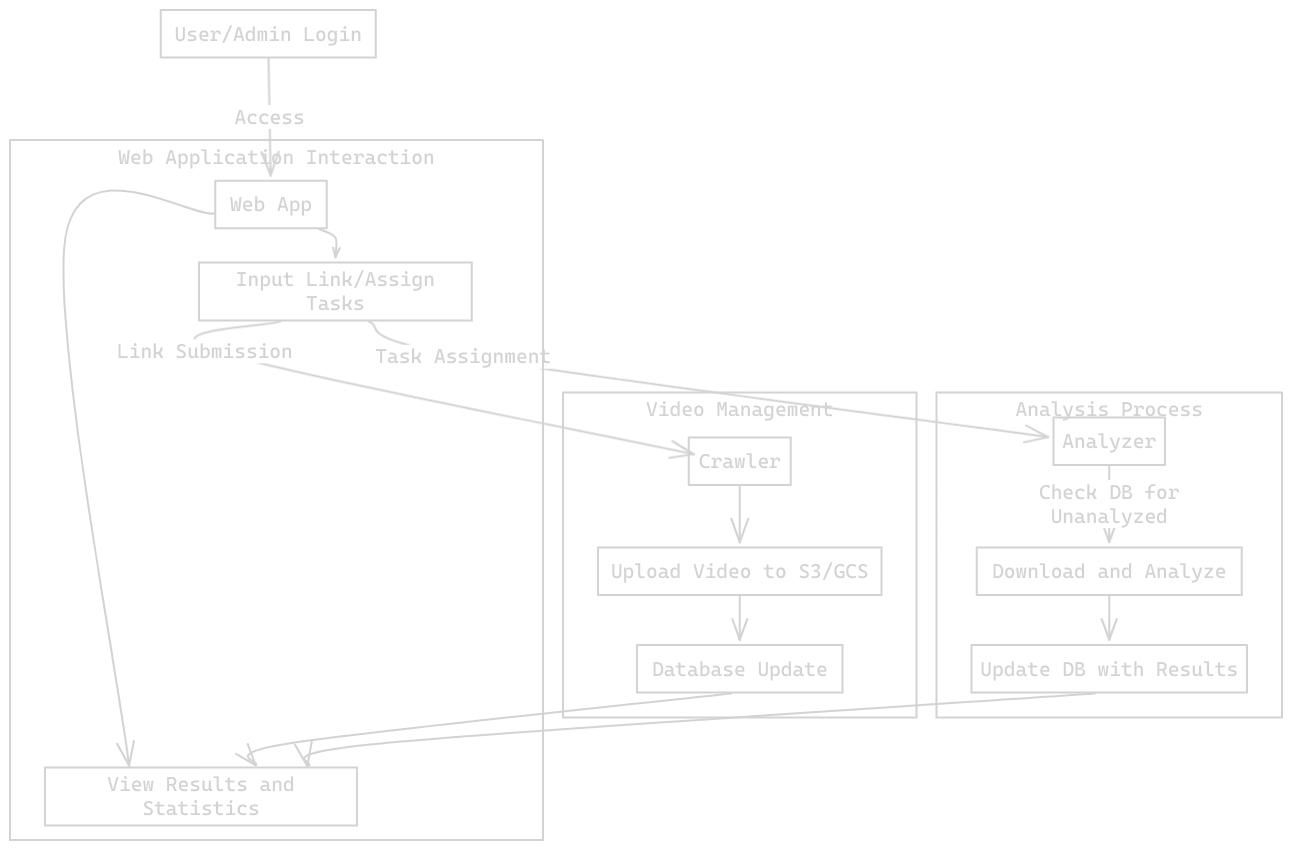
High level flow: 1. Crawler discovers and downloads videos, uploads them to object storage, and creates metadata records. 2. Analyzer samples frames, detects faces, runs deepfake models, aggregates results, and writes back a verdict. 3. API + Web expose users, videos, detections, and analytics with role-based access.
Pipeline, in practice
Crawler
- Stack: Headless Chrome (Selenium) for navigation + banner handling, custom scroll logic, and link extraction;
yt-dlpfor robust media download. - Naming & storage: Filenames are sanitized and prefixed with ISO timestamps. Videos land in Google Cloud Storage; metadata (source URL, duration, hashtags, storage URL) is posted to the API.
- Backoff & retries: Exponential backoff around fetches, checksum validation, and idempotent uploads keep the pipeline stable during bursts.
Analyzer
- Frame policy: Decode with OpenCV and sample at fixed intervals (e.g., every 5th frame). This balances speed and coverage for short clips.
- Face focus: Detect faces using a fast Haar cascade; crop with a safety margin; convert BGR→RGB for model processors. If no face is found, we still evaluate the raw frame to avoid blind spots.
- Models: Plug-and-play classifiers loaded from Hugging Face (e.g., ViT-based and CNN-based detectors). Each returns logits → softmax per frame.
- Aggregation: Majority vote across frames; confidence = mean probability of the winning class. We store per-frame traces for audits.
- Packaging: Shipped as a Google Cloud Function (Python 3.10) with increased memory for inference. Concurrency gives elastic scale without babysitting servers.
API & Web
- API: FastAPI served by Uvicorn. Endpoints cover users, videos, detections, models, and analytics. All writes are atomic; responses include model id, confidence, and timestamps for traceability.
- Data model (MongoDB):
videos: source URL, storage URL, duration, counts, hashtags, uploader, crawl timestamps.detections: video id, model id, per-frame scores, aggregated verdict, confidence, analyzer version.users&reviews: roles, verification decisions, and comments to close the human-in-the-loop loop.
- UI: A small Flask app lists videos, shows verdicts and confidences, and lets admins filter by model, date range, or hashtag.
Reliability, ops, and cost
- Stateless workers: Crawler and analyzer are stateless; progress lives in the DB. That makes retries safe and parallelization easy.
- Cold starts & throughput: Analyzer runs well as a Cloud Function; for heavier models we can drop it into Cloud Run to tame cold starts and pin CPU/RAM.
- Observability: Structured logs with request ids, per-stage timings, and model versions. Basic metrics: crawl rate, analyzer latency, success/error ratios, and queue depth.
- Security: API keys with scoped permissions, signed GCS URLs, and strict validation (Pydantic) on all incoming payloads.
Results that mattered
- On our short-form test set the ensemble produced a sub-20% false-accept rate, with room to improve as we add harder negatives and temporal cues.
- The pipeline kept up with bursty crawls thanks to object storage + elastic compute, without us managing servers.
Engineering notes
- Small conventions compound: timestamped filenames, idempotent uploads, and strict schemas saved hours of debugging.
- Ensemble > single model for this domain. Disagreement is normal; the system is designed to quarantine uncertainty rather than over-promise.
- Human review is first-class. A single click can flip a verdict and mark a sample for retraining.
What’s next
- Model quality: Curate tougher negatives, add lightweight per-creator adapters, and explore temporal signals (blink rate, head-pose drift) to reduce single-frame bias.
- Throughput: Batch inference on Cloud Run for GPU bursts when needed; keep the API on App Engine for simplicity.
- Coverage: Expand beyond a single platform, normalize metadata across sources, and schedule re-checks when models improve.